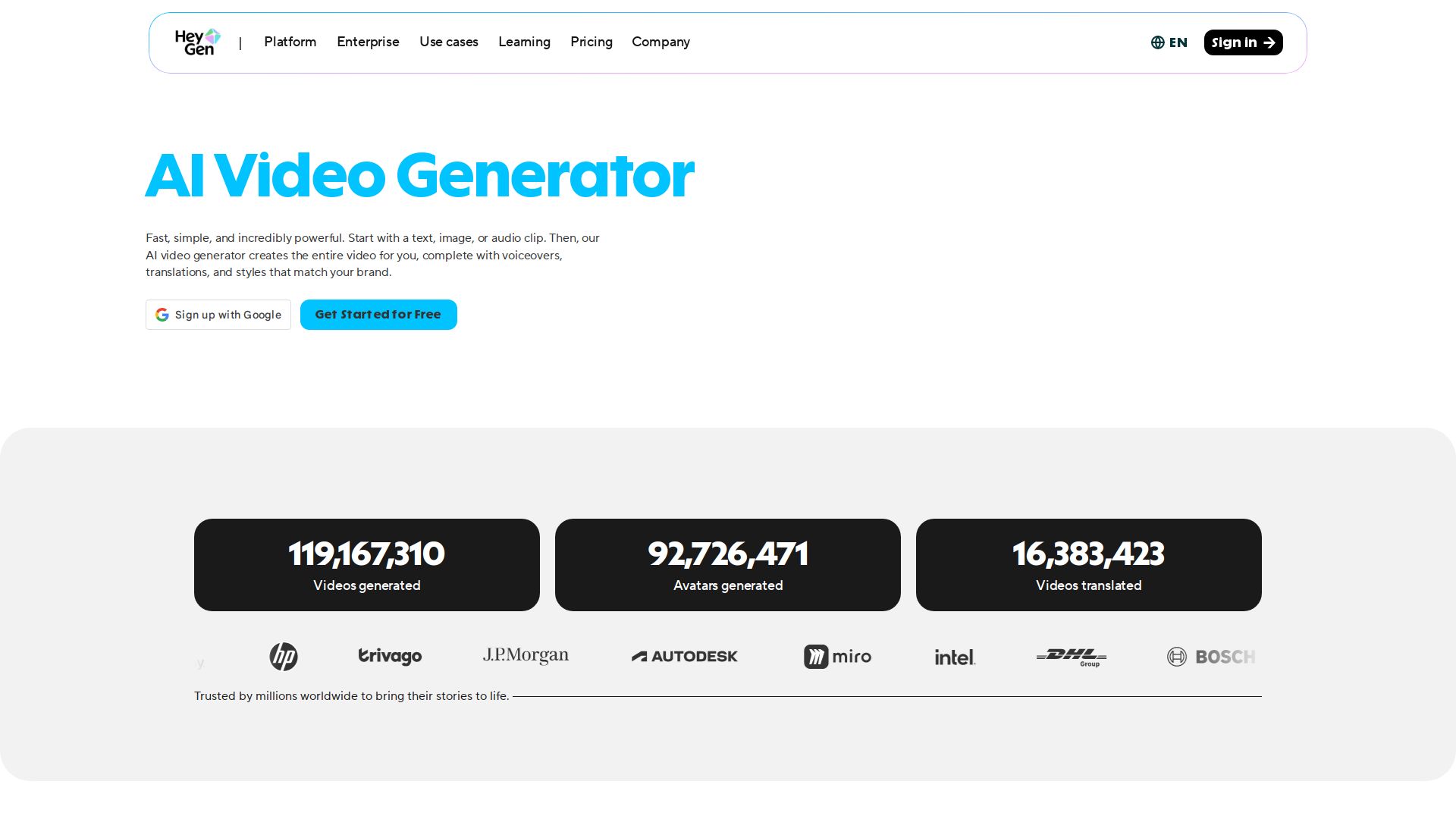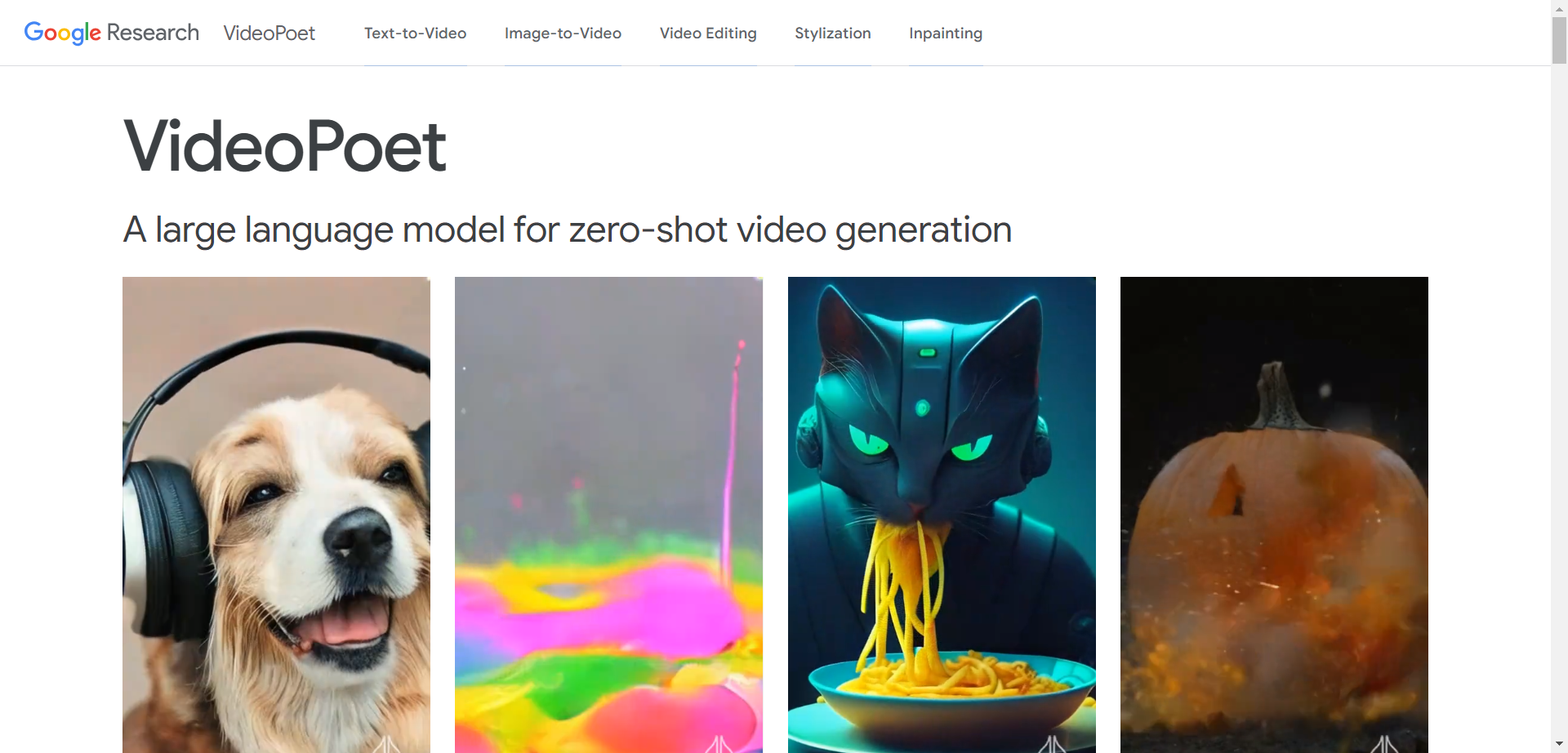
VideoPoet, by Google Research, represents a significant evolution in video generation, particularly in producing large, interesting, and high-fidelity motions.
This tool is used to convert autoregressive language models into a high-quality video generator. It includes components such as MAGVIT V2 video tokenizer and SoundStream audio tokenizer that transform images, video, and audio clips with variable lengths into a sequence of discrete codes in a unified vocabulary.
These codes are allied with text-based language models, allowing integration with other modalities such as text. An autoregressive language model, contends within this tool, learns across video, image, audio, and text modalities to autoregressively predict the next video or audio token in the sequence.
It further combines multimodal generative learning objectives into the training framework, such as text-to-video, text-to-image, image-to-video, video frame continuation, video inpainting and outpainting, video stylization, and video-to-audio.
VideoPoet can generate videos in square orientation or portrait to cater for short-form content. It also supports generating audio from a video input.
With capability of multitasking on a variety of video-centric inputs and outputs, VideoPoet illustrates how language models can synthesize and edit videos with desirable temporal consistency.