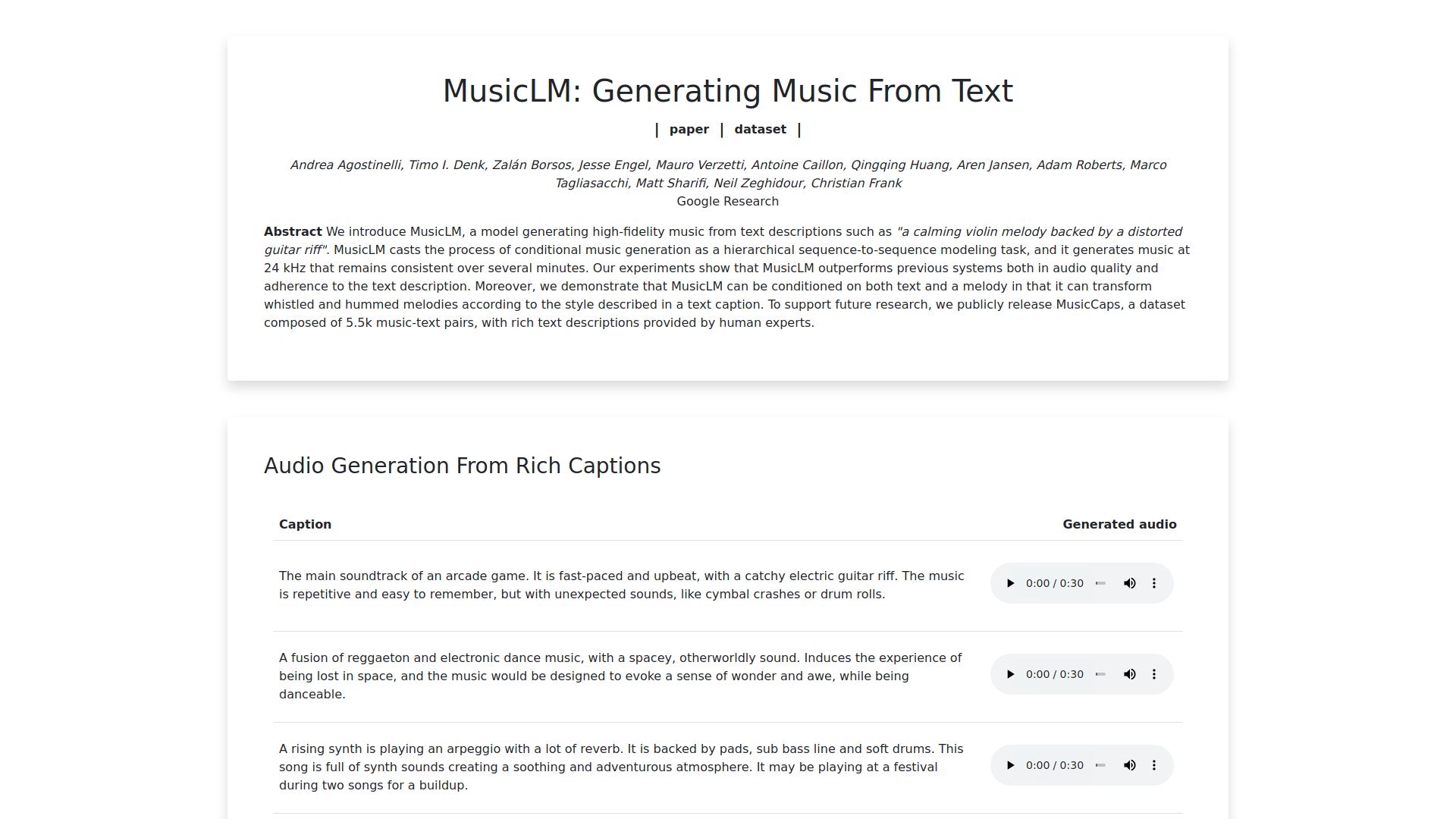
MusicLM pioneers a groundbreaking approach to conditional music generation, framing it as a hierarchical sequence-to-sequence modeling task. This innovative system produces high-quality music at a sample rate of 24 kHz, maintaining consistency over extended durations. Through rigorous experimentation, MusicLM surpasses previous models in both audio fidelity and fidelity to the provided text descriptions. Additionally, MusicLM showcases its versatility by accommodating conditioning on both textual descriptions and melodies, enabling the transformation of whistled and hummed melodies to match the specified style outlined in a textual caption. In a commitment to advancing research in this domain, MusicLM introduces MusicCaps, a publicly available dataset comprising 5.5k meticulously curated music-text pairs, enriched with detailed text descriptions crafted by human experts.
Hierarchical Sequence-to-Sequence Modeling: MusicLM adopts a novel hierarchical sequence-to-sequence modeling approach to achieve superior performance in conditional music generation tasks.
High-Quality Music Generation: With MusicLM, users can generate music at a remarkable sample rate of 24 kHz, ensuring exceptional audio quality that remains consistent over prolonged durations.
Improved Adherence to Text Descriptions: Through rigorous experimentation, MusicLM demonstrates enhanced fidelity to the provided textual descriptions, surpassing the performance of previous systems in accurately reflecting the intended musical style and content.
Dual Conditioning on Text and Melody: MusicLM exhibits versatility by accommodating conditioning on both textual descriptions and melodies. This capability enables the transformation of whistled and hummed melodies to align with the stylistic attributes outlined in textual captions.
Public Release of MusicCaps Dataset: In support of future research endeavors, MusicLM introduces MusicCaps, a comprehensive dataset comprising 5.5k meticulously curated music-text pairs. Each pair is accompanied by rich and detailed text descriptions, meticulously crafted by human experts to facilitate diverse research applications.
MusicLM's advancements hold significant implications for various domains, including music composition, content creation, and artificial intelligence research. By offering an unparalleled level of control and fidelity in conditional music generation, MusicLM opens doors to new creative possibilities and applications in music production, personalized content generation, and entertainment.
Imagine a music producer using MusicLM to effortlessly generate customized soundtracks tailored to specific moods or themes outlined in textual descriptions. Furthermore, MusicLM's ability to transform whistled and hummed melodies according to desired styles offers immense potential for enhancing user creativity and musical expression.
MusicLM represents a paradigm shift in conditional music generation, leveraging hierarchical sequence-to-sequence modeling to deliver high-quality, consistent music aligned with textual descriptions and melodies. With its superior performance, versatility, and the release of the MusicCaps dataset, MusicLM paves the way for transformative advancements in music generation research and applications.