
One big downside of Whisper is though, that it can not tell you who is speaking in a conversation. That's a problem when analyzing conversations. This is where diarization comes in. Diarization is the process of identifying who is speaking in a conversation.
In this tutorial you will learn how to identify the speakers, and then match them with the transcriptions of Whisper. We will use pyannote-audio to accomplish this. Let's get started!
First, we need to prepare the audio file. We will use the first 20 minutes of Lex Fridmans podcast with Yann LeCun. To download the video and extract the audio, we will use yt-dlp package.

We will also need ffmpeg installed

Now we can do the actual download and audio extraction via the command line.

Now we have the download.wav file in our working directory. Let's cut the first 20 minutes of the audio. We can use the pydub package for this with just a few lines of code.

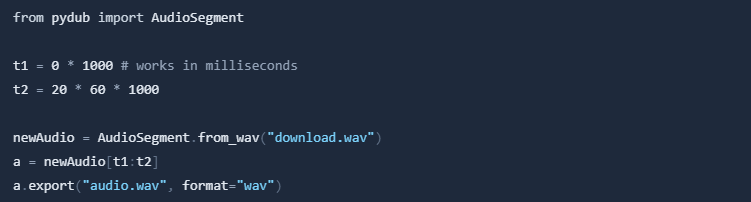
audio.wav is now the first 20 minutes of the audio file.
pyannote.audio is an open-source toolkit written in Python for speaker diarization. Based on PyTorch machine learning framework, it provides a set of trainable end-to-end neural building blocks that can be combined and jointly optimized to build speaker diarization pipelines. pyannote.audio also comes with pretrained models and pipelines covering a wide range of domains for voice activity detection, speaker segmentation, overlapped speech detection, speaker embedding reaching state-of-the-art performance for most of them.
Installing Pyannote and running it on the video audio to generate the diarizations.



Lets print this out to see what it looks like.

The output:
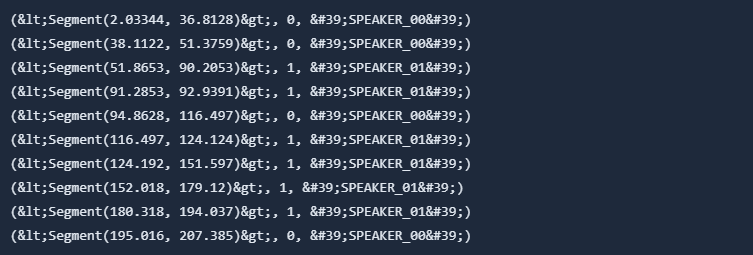
This looks pretty good already, but let's clean the data a little bit:
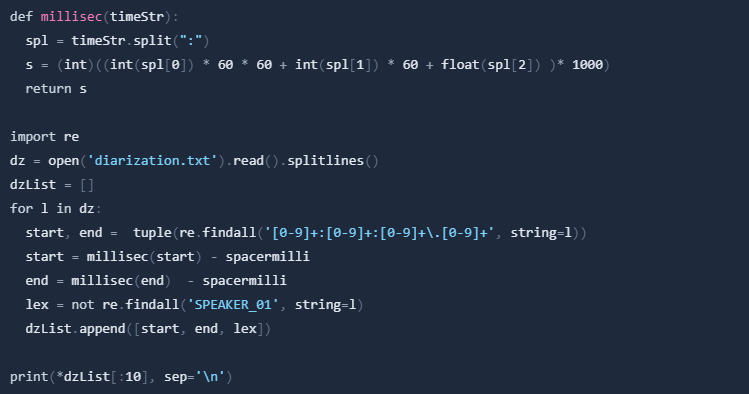

Now we have the diarization data in a list. The first two numbers are the start and end time of the speaker segment in milliseconds. The third number is a boolean that tells us if the speaker is Lex or not.
Next, we will attach the audio segements according to the diarization, with a spacer as the delimiter.
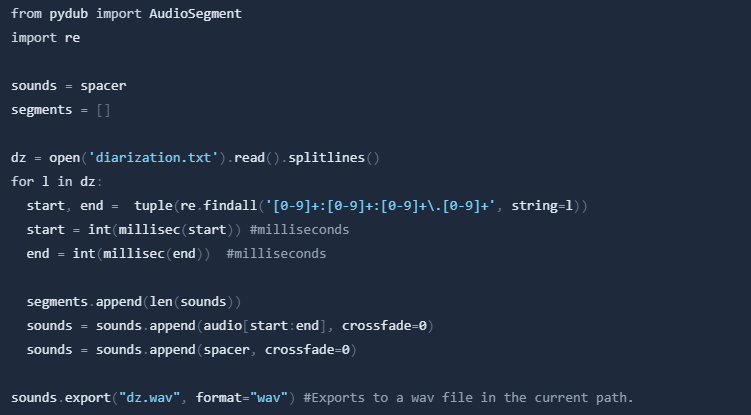


Next, we will use Whisper to transcribe the different segments of the audio file. Important: There is a version conflict with pyannote.audio resulting in an error. Our workaround is to first run Pyannote and then whisper. You can safely ignore the error.
Installing Open AI Whisper.

Running Open AI whisper on the prepared audio file. It writes the transcription into a file. You can adjust the model size to your needs. You can find all models on the model card on Github.


In order to work with .vtt files, we need to install the webvtt-py library.

Lets take a look at the data:


Next, we will match each transcribtion line to some diarizations, and display everything by generating a HTML file. To get the correct timing, we should take care of the parts in original audio that were in no diarization segment. We append a new div for each segment in our audio.
# we need this fore our HTML file (basicly just some styling)
preS = '<!DOCTYPE html>\n<html lang="en">\n <head>\n <meta charset="UTF-8">\n <meta name="viewport" content="width=device-width, initial-scale=1.0">\n <meta http-equiv="X-UA-Compatible" content="ie=edge">\n <title>Lexicap</title>\n <style>\n body {\n font-family: sans-serif;\n font-size: 18px;\n color: #111;\n padding: 0 0 1em 0;\n }\n .l {\n color: #050;\n }\n .s {\n display: inline-block;\n }\n .e {\n display: inline-block;\n }\n .t {\n display: inline-block;\n }\n #player {\n\t\tposition: sticky;\n\t\ttop: 20px;\n\t\tfloat: right;\n\t}\n </style>\n </head>\n <body>\n <h2>Yann LeCun: Dark Matter of Intelligence and Self-Supervised Learning | Lex Fridman Podcast #258</h2>\n <div id="player"></div>\n <script>\n var tag = document.createElement(\'script\');\n tag.src = "https://www.youtube.com/iframe_api";\n var firstScriptTag = document.getElementsByTagName(\'script\')[0];\n firstScriptTag.parentNode.insertBefore(tag, firstScriptTag);\n var player;\n function onYouTubeIframeAPIReady() {\n player = new YT.Player(\'player\', {\n height: \'210\',\n width: \'340\',\n videoId: \'SGzMElJ11Cc\',\n });\n }\n function setCurrentTime(timepoint) {\n player.seekTo(timepoint);\n player.playVideo();\n }\n </script><br>\n'
postS = '\t</body>\n</html>'
from datetime import timedelta
html = list(preS)
for i in range(len(segments)):
idx = 0
for idx in range(len(captions)):
if captions[idx][0] >= (segments[i] - spacermilli):
break;
while (idx < (len(captions))) and ((i == len(segments) - 1) or (captions[idx][1] < segments[i+1])):
c = captions[idx]
start = dzList[i][0] + (c[0] -segments[i])
if start < 0:
start = 0
idx += 1
start = start / 1000.0
startStr = '{0:02d}:{1:02d}:{2:02.2f}'.format((int)(start // 3600),
(int)(start % 3600 // 60),
start % 60)
html.append('\t\t\t<div class="c">\n')
html.append(f'\t\t\t\t<a class="l" href="#{startStr}" id="{startStr}">link</a> |\n')
html.append(f'\t\t\t\t<div class="s"><a href="javascript:void(0);" onclick=setCurrentTime({int(start)})>{startStr}</a></div>\n')
html.append(f'\t\t\t\t<div class="t">{"[Lex]" if dzList[i][2] else "[Yann]"} {c[2]}</div>\n')
html.append('\t\t\t</div>\n\n')
html.append(postS)
s = "".join(html)
with open("lexicap.html", "w") as text_file:
text_file.write(s)
print(s)












