
In this tutorial we will utilize Qdrant Vector Database to store Embeddings from Cohere's model and search using cosine similarity. We will use Cohere SDK to access the model. So, without any further ado, let’s jump in!
I will use Qdrant Cloud to host my Database. And good to know, that Qdrant provides 1 GB of free forever memory. So go and use Qdrant Cloud. You can find out how to do it here.
Now let's create a new virtual environment inside project directory and install the required packages:

Please create a project .py file.

We will store our data in JSON format. Feel free to copy it:
[
{ "key": "Lion", "desc": "Majestic big cat with golden fur and a loud roar." },
{ "key": "Penguin", "desc": "Flightless bird with a tuxedo-like black and white coat." },
{ "key": "Gorilla", "desc": "Intelligent primate with muscular build and gentle nature." },
{ "key": "Elephant", "desc": "Large mammal with a long trunk and gray skin." },
{ "key": "Koala", "desc": "Cute and cuddly marsupial with fluffy ears and a big nose." },
{ "key": "Dolphin", "desc": "Playful marine mammal known for its intelligence and acrobatics." },
{
"key": "Orangutan",
"desc": "Shaggy-haired great ape found in the rainforests of Borneo and Sumatra."
},
{ "key": "Giraffe", "desc": "Tallest land animal with a long neck and spots on its fur." },
{
"key": "Hippopotamus",
"desc": "Large, semi-aquatic mammal with a wide mouth and stubby legs."
},
{ "key": "Kangaroo", "desc": "Marsupial with powerful hind legs and a long tail for balance." },
{ "key": "Crocodile", "desc": "Large reptile with sharp teeth and a tough, scaly hide." },
{
"key": "Chimpanzee",
"desc": "Closest relative to humans, known for its intelligence and tool use."
},
{ "key": "Tiger", "desc": "Striped big cat with incredible speed and agility." },
{ "key": "Zebra", "desc": "Striped mammal with a distinctive mane and tail." },
{ "key": "Ostrich", "desc": "Flightless bird with long legs and a big, fluffy tail." },
{ "key": "Rhino", "desc": "Large, thick-skinned mammal with a horn on its nose." },
{ "key": "Cheetah", "desc": "Fastest land animal with a spotted coat and sleek build." },
{
"key": "Polar Bear",
"desc": "Arctic bear with a thick white coat and webbed paws for swimming."
},
{ "key": "Peacock", "desc": "Colorful bird with a vibrant tail of feathers." },
{ "key": "Kangaroo", "desc": "Marsupial with powerful hind legs and a long tail for balance." },
{
"key": "Octopus",
"desc": "Intelligent sea creature with eight tentacles and the ability to change color."
},
{ "key": "Whale", "desc": "Enormous marine mammal with a blowhole on top of its head." },
{ "key": "Sloth", "desc": "Slow-moving mammal found in the rainforests of South America." },
{ "key": "Flamingo", "desc": "Tall, pink bird with long legs and a curved beak." }
]
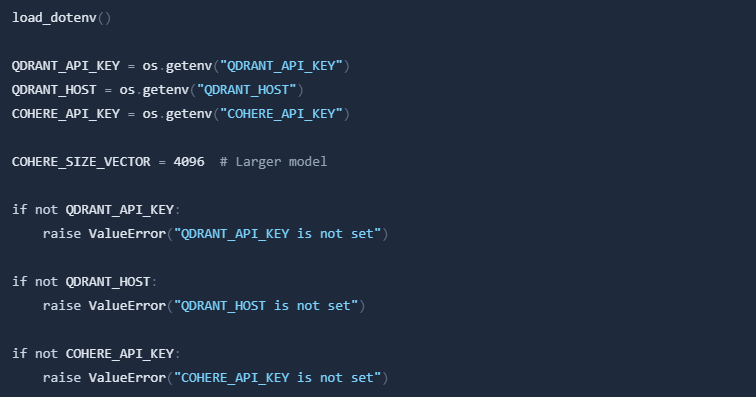
Create .env file and store your Cohere API key, Qdrant API key and Qdrant host there:


I will implement the SearchClient class, which will be able to index and access our data. Class will contain all necessary functionalities, such as indexing and searching, but also data conversion to necessary formats.
class SearchClient:
def __init__(
self,
qdrabt_api_key: str = QDRANT_API_KEY,
qdrant_host: str = QDRANT_HOST,
cohere_api_key: str = COHERE_API_KEY,
collection_name: str = "animal",
):
self.qdrant_client = QdrantClient(host=qdrant_host, api_key=qdrabt_api_key)
self.collection_name = collection_name
self.qdrant_client.recreate_collection(
collection_name=self.collection_name,
vectors_config=models.VectorParams(
size=COHERE_SIZE_VECTOR, distance=models.Distance.COSINE
),
)
self.co_client = cohere.Client(api_key=cohere_api_key)
# Qdrant requires data in float format
def _float_vector(self, vector: List[float]):
return list(map(float, vector))
# Embedding using Cohere Embed model
def _embed(self, text: str):
return self.co_client.embed(texts=[text]).embeddings[0]
# Prepare Qdrant Points
def _qdrant_format(self, data: List[Dict[str, str]]):
points = [
models.PointStruct(
id=uuid.uuid4().hex,
payload={"key": point["key"], "desc": point["desc"]},
vector=self._float_vector(self._embed(point["desc"])),
)
for point in data
]
return points
# Index data
def index(self, data: List[Dict[str, str]]):
"""
data: list of dict with keys: "key" and "desc"
"""
points = self._qdrant_format(data)
result = self.qdrant_client.upsert(
collection_name=self.collection_name, points=points
)
return result
# Search using text query
def search(self, query_text: str, limit: int = 3):
query_vector = self._embed(query_text)
return self.qdrant_client.search(
collection_name=self.collection_name,
query_vector=self._float_vector(query_vector),
limit=limit,
)
Let's try to read data from the data.json file, process and index it. Then we can try to search and get top 3 results from our Database!
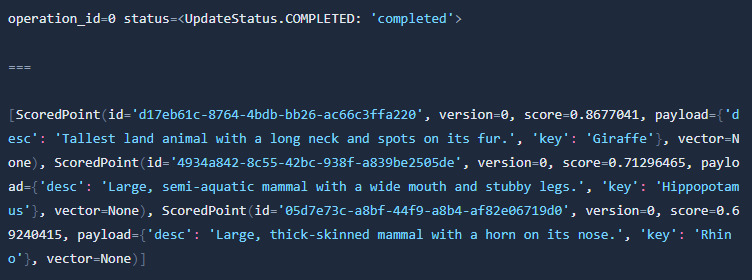
As you can see in 1st row: index operation went well. We got 3 results, as we defined. The 1st one is (as expected) a Giraffe. We also got Hippopotamus and Rhino. They are also huge, but I think Giraffe is the tallest 😆.

To practice your Qdrant skills, I recommend building an API that will allow your application to index data, add new records and search. I think you can utilize FastAPI for that!
And if you want to go wild with the new skills, I would recommend you to use them to build an AI based application during the Cohere x Qdrant AI Hackathon this weekend!












