
🔑 Note: For this tutorial I will use Google Colab as I do not have a computer with a GPU. You can use your local computer. Remember to use GPU!
First, we need to install the depedencies we need. We will install FFmpeg - tool to record, convert and stream audio and video.

Now I will install necessary packages:
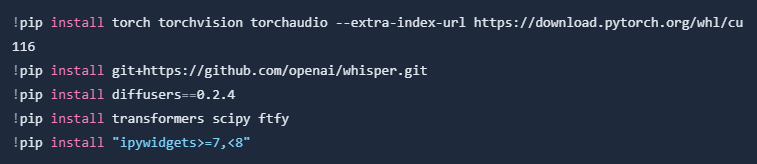
🔑 Note: If you have any problems installing Whisper go here.
Next step is authentication of the Stable Diffusion with Hugging Face.

Now we will check if we are using GPU.

Okay, now we are ready to start!
🔑 Note: To not lose time I recorded my prompt and put it in main directory.
We will start by extracting my prompt from file, using OpenAI's Whisper small model. There are some bigger and smaller models, you can choose which you will use.
For extraction I utilized code from official repository. I also added some "tips" to the end of the prompt.
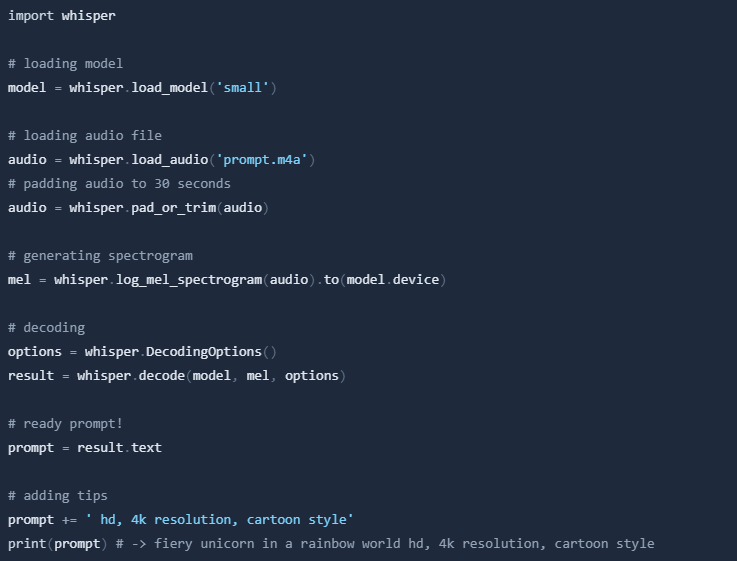
Now we will use Stable Diffusion for generating image from text. Let's load model.
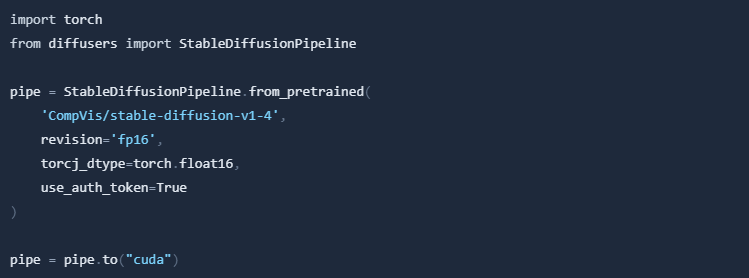
Using pipe we can generate image from text.

Let's check our result using:


Our result!
Wow! Maybe our result could be better, but we didn't change any parameters. The most important thing is that we are able to generate an image with our voice. Isn't that great? Remember what we were able to do 10 years ago and what we can do today!
Hope you had as much fun as I did creating this program. Thank you and I hope you will check back here!












