
As an example for this tutorial we imagine that we own a hotel and we want to answer questions from our customers. Questions come in all different languages and we want to answer them with a single answer in English. We will use the Coheres' new multilingual model to cluster the questions to see which questions are similar. Coheres new model is the industry’s first multilingual text understanding model that supports 100+ languages and delivers 3X better performance than existing open-source models.
This is just one usecase for Coheres' new multilingual model. For example you could use it for these three usecases (and more of course):
Multilingual Semantic Search: To improve the quality of search results, Cohere’s multilingual model can produce fast, accurate results regardless of the language used in the search query or source content.
Aggregate Customer Feedback: Cohere’s multilingual model can be deployed to organize customer feedback across hundreds of languages, simplifying a major challenge for international operations.
Cross-Lingual Zero-Shot Content Moderation: Identifying harmful content in online global communities is challenging. By training Cohere’s multilingual model with a few English examples, it can then detect harmful content in 100+ languages.
Before we start with our hotel example, let's have a quick look at how Coheres' new multilingual model works. Cohere's multilingual text understanding model uses a technique called semantic vector space mapping to position texts with similar meanings in close proximity, which enables a range of valuable use cases for multilingual settings. For example, one can map a query to this vector space during a search to locate relevant documents nearby, which often yields better search results than keyword search. To train these models, however, large quantities of training data are needed, and this data has historically been mostly available in English. Prior work has attempted to use machine translation to map this data to other languages, but this approach does not capture the nuances behind language usage in different countries. In contrast, this new model is trained on a dataset of nearly 1.4 billion question/answer pairs across hundreds of languages, which are an actual questions asked by speakers of those languages, allowing to capture language- and country-specific nuances.
Let's get started. For our hotel questions example we will use the following questions:
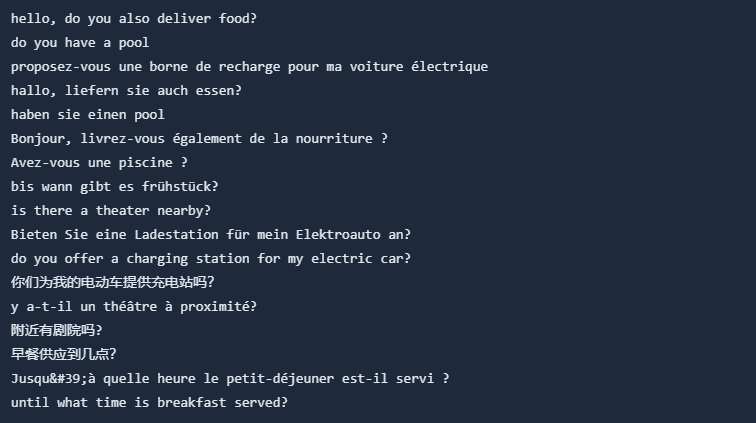
You can see that the questions are in different languages. English, German, French and Chinese. Upon closer inspection you can see that some of the questions are very similar. Overall 5 topic clusters can be identified:
Food
Pool
Charging Station
Theater
Breakfast
Let's automate this process of clustering with Coheres' new multlingual model. We recommend to use the playground to test the model and to get a feeling for it. You can find the playground here.
Let's add our questions to the 'Texts' field like so:

On the right side you can set parameters. Change the model to 'multilingual-22-12' and truncate to 'None'. Then click on 'Calculate'. You will see that the model has clustered the questions into 5 clusters.

Now you can see that the model has clustered the questions into 5 clusters. Points that are close to each other are similar. Now you can answer the questions with a single answer.
But let's move from Coheres Playground to our own code. You can export this current example with the button 'Export code'. Choose the programming language you want to use. We will use Python.
From here you can continue to use the embeddings for your own use case.












