

Stable Diffusion is a text-to-image latent diffusion model created by the researchers and engineers from CompVis, Stability AI and LAION. It's trained on 512x512 images from a subset of the LAION-5B database. This model uses a frozen CLIP ViT-L/14 text encoder to condition the model on text prompts. With its 860M UNet and 123M text encoder, the model is relatively lightweight and runs on most GPUs. If you want to learn more continue reading here.

You need to accept the model license before downloading or using the weights. In this tutorial we'll use model version v1-4, so you'll need to visit its card, read the license and tick the checkbox if you agree.
You have to be a registered user in 🤗 Hugging Face Hub, and you'll also need to use an access token for the code to work. For more information on access tokens, please refer to this section of the documentation.

Now we will login into 🤗 Hugging Face. You can use the notebook_login function to login.

After this we will get started with the Image2Image pipeline.
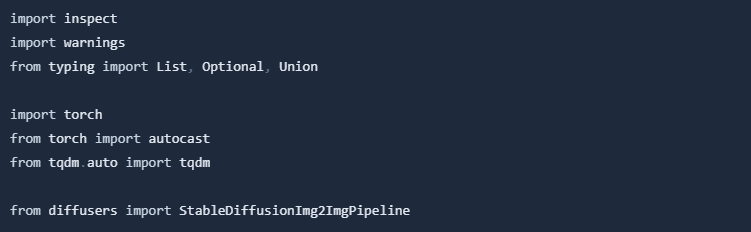
Load the pipeline.
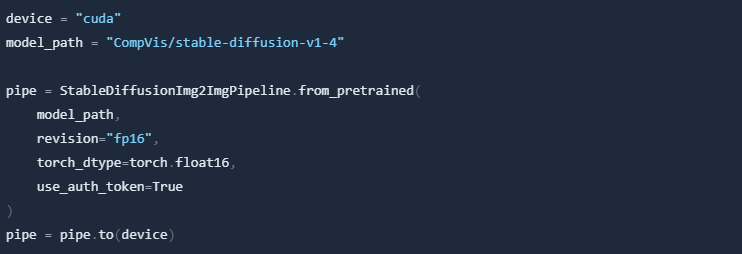
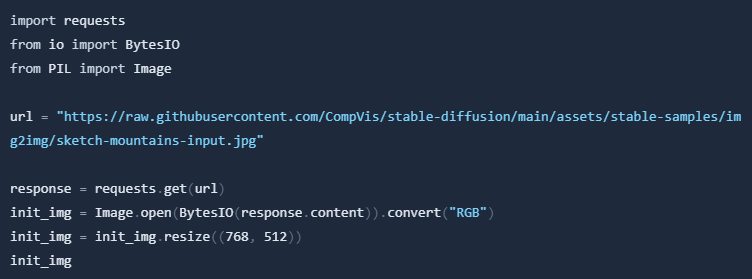
Download an initial image and preprocess it so we can pass it to the pipeline.

Define the prompt and run the pipeline.

Here, strength is a value between 0.0 and 1.0, that controls the amount of noise that is added to the input image. Values that approach 1.0 allow for lots of variations but will also produce images that are not semantically consistent with the input.

In Colab you can print out the image by just typing:

And there you have it! A beautiful AI generated artwork from a simple sketch.

Futhermore, you can tune the parameters and test what work best for your usecase. As you can see, when using a lower value for strength, the generated image is more closer to the original init_image:













