
Semantic search engines have many practical applications. For example, StackOverflow's "similar questions" feature is enabled by such a search engine. Additionally, they can be used to build a private search engine for internal documents or records. This article will show you how to build a basic semantic search engine. This article covers the usage of an archive of questions to embed, search with an index and nearest neighbour search and visualization based on the embeddings.
For this Cohere AI tutorial we will use the example data that is provided by Cohere. You can find the full notebook code here
First we will get get the archive of questions, then embed them and finally search using an index and nearest neighbour search. At the end we will visualize the results based on the embeddings. To run this tutorial you will need to have a Cohere account. You can sign up for a free account here.
Lets start by installing the necessary libraries.

Then create a new notebook or Pythin file and import the necessary libraries.

Next, we will get the archive of questions from Cohere. This archive is the trec dataset, which is a collection of questions with categories. We will use the load_dataset function from the datasets library to load the dataset.
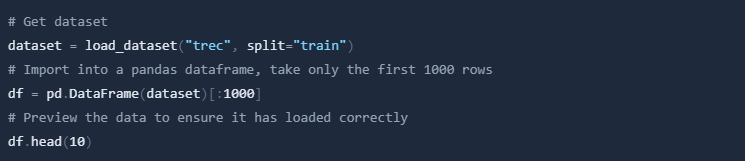

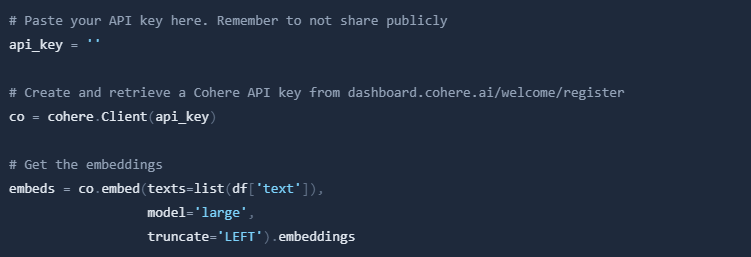
Now we can embed the questions using Cohere. We will use the embed function from the Cohere library to embed the questions. It should only take a few seconds to generate one thousand embeddings of this length.
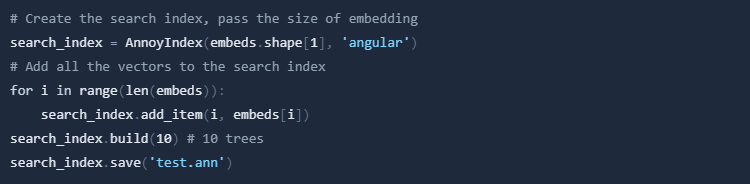
Now we can build the index and search for the nearest neighbours. We will use the AnnoyIndex function from the annoy library. The optimization problem of finding the point in a given set that is closest (or most similar) to a given point is known as nearest neighbour search.
We can use the index we built to find the nearest neighbours of both existing questions and new questions that we embed. If we're only interested in measuring the similarities between the questions in the dataset (no outside queries) a simple way is to calculate the similarities between every pair of embeddings we have.


We can use a technique such as embedding to find the nearest neighbours of a user query. By embedding the query, we can measure its similarity with items in the dataset and identify the closest neighbours.
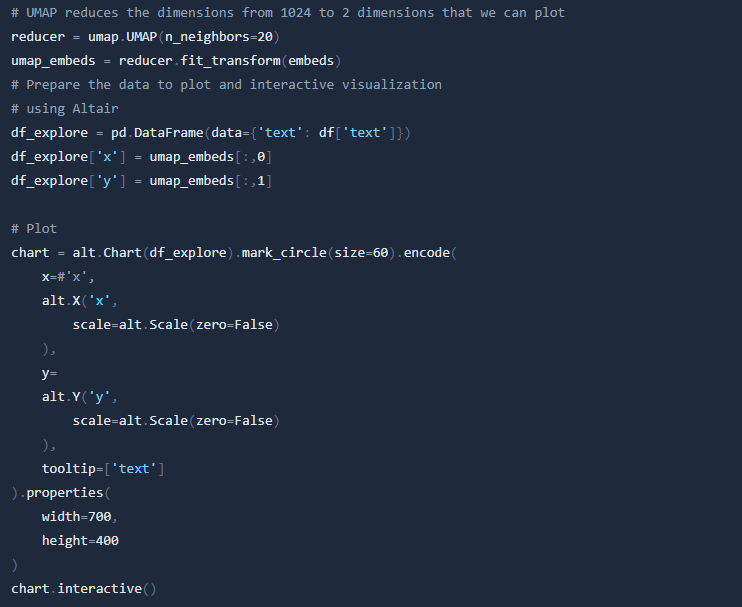

This brings us to an end to this introductory guide on semantic search using sentence embeddings. Going forward, when constructing a search product, there are additional factors to consider (e.g. handling lengthy texts or training to optimize the embeddings for a particular purpose). Feel free to explore and experiment with other data.












